David's Cubicle

Let's talk, chitchat, and grab coffee :)
This project is a Project Course referred to CS 122C from Prof. Chen Li at the University of California, Irvine. I will explain my implementation of a database system ground up from the simplest basis (Page File Mangement)… WITHOUT SHARING ANY OF MY CODE. Because it is a on-going class and for the best of student fairness, I do not want student to have any unfair advatange using my code. Please understand this is a explanatory page for people wanting to learn and understand how database system works and why it is efficient.
Last but not least, here is a overall image of how this project looks like:
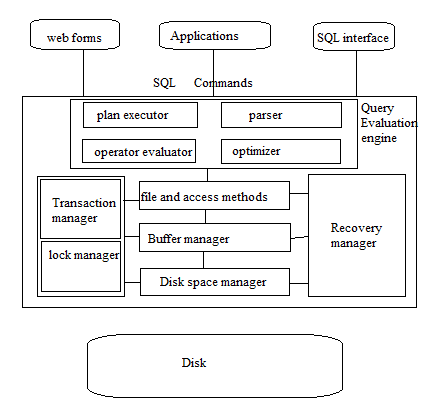
We will work from the bottom, disk space management, and in our case, we call it page file management.
Part 1 (Project 1)
Page File Management (PFM): PFM contains 4 functions that act with clear purpose: create, destroy, open, and close the file. Particularly, this is a single instance in the later object class that will only does these functionalities to create separation of layers for clean design and optimization.
PFM is a file management that used very similar to the OS file management except for a few twists. First of all it does not contain a pointer per se (with bunch of other information contain inside of the pointers). PFM simply has a pass-by-reference variable of a Object called FileHandler (class of FileHandle) when to open the file to manipulate the data into the disk. It contains some information about the opened file, such as number of read, write, append, and of course, the file name. It does not really have a pointer point to the file because we did not want to leave any dangling pointer (of course based on the implementation it should not be a problem if we are sophisticated). But the another reason for not having a pointer is basically saving the resource.
In the Filehandler, you have four additional functions: read a page, write a page, append a page, and get the total number of page. In context, a page is defined 4 KB which means 4096 (2^12) bytes each time you try to access a “page”. It is used from a database perspective to create a level of readability and simplicity.
This is what it looks like:
PFM:
- create:
- create the file and of course if file already exists, there would be no file created
- destroy:
- destroy the file that is being created ONLY if it exists
- open:
- file contains information about the counter, so it will write it to the FileHandle
- FileHandle will get the information (counters, file name) it needs for file manipulation.
- close:
- close the FileHandle properly so that information about the counter will write back to the file
FH:
- read:
- read the actual “fileName” of a given page if the file name exists
- write:
- write a certain page into the file (disk)
- append:
- write to the end of the file (given the total page of the file)
- totalPage:
- basically, return the total page of you appened.
Part 2 (Project 2)
Relation Manager: After the RBFM and PFM, we have continued to implement a wrapping layer of RBFM to handle relationship tables for databases. More specifically, we use columns-like tables to record tables’ information.
- format shown below:
- Tables (table-id:int, table-name:varchar(50), file-name:varchar(50))
- Columns(table-id:int, column-name:varchar(50), column-type:int, column-length:int, column-position:int)
- Example shown below:
- Tables:
- (1, “Tables”, “Tables”)
- (2, “Columns”, “Columns”)
- Columns:
- (1, “table-id”, TypeInt, 4 , 1)
- (1, “table-name”, TypeVarChar, 50, 2)
- (1, “file-name”, TypeVarChar, 50, 3)
- (2, “table-id”, TypeInt, 4, 1)
- (2, “column-name”, TypeVarChar, 50, 2)
- (2, “column-type”, TypeInt, 4, 3)
- (2, “column-length”, TypeInt, 4, 4)
- (2, “column-position”, TypeInt, 4, 5)
- Tables:
- Say now i want to insert a new table called “Employee”:
- In Tables, I will add a record:
- (3, “Employee”, “Employee”)
- In Columns, I will add records:
- (3, “empname”, TypeVarChar, 30, 1)
- (3, “age”, TypeInt, 4, 2)
- (3, “height”, TypeReal, 4, 3)
- (3, “salary”, TypeInt, 4, 4)
- In Tables, I will add a record:
Part 3 (Project 3)
Now, it is important to have the database ready; however, it is not enough to do any query search or comparison query at current stage. Now, we have implemented a B+ tree to further integrate our project:
Our implementation design of index Entry:
- Entries on internal nodes:
- each key has its left-page number and right-page number
- and the entry has the length of the string if it is varchar otherwise it is just 4 bytes of float or int
-
[LPageNum <(lengthOfVarChar and varchar or just float/int), (RID)> RPageNum]
- Entries on leaf nodes:
- each key has its left-page number and right-page number, in the leaf node, Left and Right page number are remained -1 as always it is used only because of the generalization of the structure
- and the entry has the length of the string if it is varchar otherwise it is just 4 bytes of float or int
-
[-1 <(lengthOfVarChar and varchar or just float/int), (RID)> -1]
Our page design choice:
- Internal-page (non-leaf node) design.
- a flag to show this node’s type (int nodeType).
- a number of bytes that are free (short freeBytes).
- a number of keys/slots that are being used (short slotNums)
- an offset for nextLeaf and will not be used for Internal Node, allocated for leaf Node
- [L|key(RID)|R ] [L|key(RID)|R ]….. [nodeType ][freeBytes ][slotNum ][nextLeaf (UNUSED)]
- Leaf-page (leaf node) design.
- a flag to show this node’s type (int nodeType).
- a number of bytes that are free (short freeBytes).
- a number of keys/slots that are being used (short slotNums)
- an offset for nextLeaf, basically a page number used to find the next page number
- [L|key(RID)|R ] [L|key(RID)|R ]….. [nodeType ][freeBytes ][slotNum ][nextLeaf (USED)]
a quick look over split on B+ tree (again, I will not provide any code because it is a on-going class but I am happy to share my logic and to discuss if there is any optimization or better choice toward this design):
- will describe as a pseudo-code:
- InsertLeaf():
- while loop if it is not leaf:
- for loop of all keys of the current page:
- if the new key is less than i’s key: go to left page num
- if it is the end of the current page: go to right page num (last page in the rightmost)
- for loop of all keys of the current page:
- if enough space in the current leaf Node:
- insert in the right offset
- otherwise:
- split two node, original node becomes the new leaf node.
- the first key of split right-side Node gets to copy up to internal node
- if left leafNode was the root (meaning only has one node as the number of the total node:
- create a new node as the internal node and put the copy-up’ed key as the new internal key
- otherwise: call insertIntermediate
- while loop if it is not leaf:
- insertIntermediate():
- if has space in the internal node:
- insert into the right position
- otherwise:
- split and new left internal node gets the old internal node, and create a new right internal node
- in the right-sided internal node, its first key gets to PUSH up instead of COPY (meaning will get to delete the key)
- if the left node is the original root,
- create a new root and insert push-up’ed key in the first spot
- otherwise: recursively call insertIntermediate()
- if has space in the internal node:
- InsertLeaf():
Part 4 (Final Project):
The last part of the database management is the parser and optimizer for the database. It is used to help when the query pass in and choose whichever users ask for (such as Project, Filter, and Join) We have implement these functionalities:
- Project
- Filter
- Blocked-Nest-Loop Join
- Index-Nest-Loop Join
- Aggregation (min, max, count, sum, avg)
- Aggregation on Group-By
A thank-you note to professor Chen Li and the TAs in this class helped us to develop such fascinating experiences and here is a link to the project website: CompSci122c, additional work for Prof. Chen Li’s Research Texera: Texera-presentation, and its GitHub page: Texera